前段时间在学习MySQL和内核的时候,碰巧遇到twitter的dba老大在折腾numa不平衡问题的问题而写了二篇numa相关的文章,非常有技术含量。参见 这里
numa不平衡问题的解决方案摘抄如下:
A more thorough solution
The original post also only addressed only one part of the solution: using interleaved allocation.
A complete and reliable solution actually requires three things, as we found when implementing this change for production systems at Twitter:
1. Forcing interleaved allocation with numactl –interleave=all. This is exactly as described previously, and works well.
2. Flushing Linux’s buffer caches just before mysqld startup with sysctl -q -w vm.drop_caches=3. This helps to ensure allocation fairness, even if the daemon is
restarted while significant amounts of data are in the operating system buffer cache.
3. Forcing the OS to allocate InnoDB’s buffer pool immediately upon startup, using MAP_POPULATE where supported (Linux 2.6.23+), and falling back to memset otherwise. This forces the NUMA node allocation decisions to be made immediately, while the buffer cache is still clean from the above flush.
具体的代码实现参看 这里
其中就提到了如何用mmap的MAP_POPULATE来达到匿名页预先分配的问题,这是非常好的思路。
我们来man mmap看下:
MAP_POPULATE (since Linux 2.5.46)
Populate (prefault) page tables for a mapping. For a file mapping, this causes read-ahead on
the file. Later accesses to the mapping will not be blocked by page faults. MAP_POPULATE is
only supported for private mappings since Linux 2.6.23.
这个标志很早就有了,但是其实很少程序用到了这个特性,去年分析内核内存系统实现的时候,重点读过这块代码。这个特性在特殊的场景下还是挺有好处的。
我们知道通常我们mmap出来的内存,要不是匿名页面,要不就是文件的映射。当访问这块线性地址的时候,如果需要的页面不在内存中,就会发生缺页中断,内核分配物理内存,如果是文件后背的话,顺手把文件读进来。这样在高性能服务器里面分配内存的动作就会成为问题。
问题主要体现在2点:
1. 内存分配的时候,系统的内存已经比较乱了,不知道系统会从那个numa节点去分配,而且极端的时候,发生内存短缺,会换出内存页面,这个时间非常不可控。内存的分配也无法准确的指定。
2. 读文件这个时间非常不可控,系统可能会被挂起等待IO动作完成。
如果我们能够在系统内存还比较干净的时候,比如刚开机或者刚做完vm.drop_caches=3的时候,去把我们需要的内存或者数据预先按照我们设想的方式来准备,虽然这个集中化的动作会化很长的时间,但是换来的是后续的可控性。
mmap的MAP_POPULATE标志使用代码参见这里:
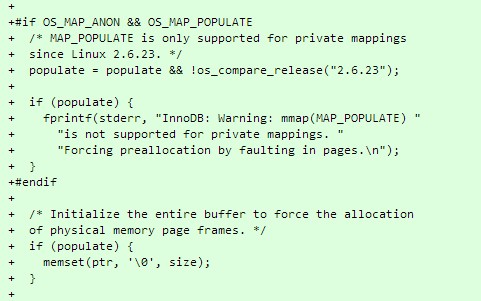
如果你的系统没有这个函数,使用memset(ptr, ‘\0’, size);也是个好的方案。
总结:高性能服务器细节多,技术含量高!
祝玩的开心!
Recent Comments