最近我们的Erlang IO密集型的服务器程序要做细致的性能提升,从每秒40万包处理提升到60万目标,需要对进程和IO调度器的原理很熟悉,并且对行为进行微调,花了不少时间参阅了相关的文档和代码。
其中最有价值的二篇文章是:
1. Characterizing the Scalability of Erlang VM on Many-core Processors 参见这里
2. Evaluate the benefits of SMP support for IO-intensive Erlang applications 参见这里
我们的性能瓶颈目前根据 lcnt 的提示:
1. 调度器运行队列的锁冲突,参见下图:

2. erlang只有单个poll set, 大量的IO导致性能瓶颈,摘抄“Evaluate the benefits of SMP support for IO-intensive Erlang applications” P46的结论如下:
Read more…
erl启动的时候有个参数 -init_debug 作用是
Makes init write some debug information while interpreting the boot script.
参见erlang system_principles的1.3节:Boot Scripts, 我们可以知道,每个erlang vm启动的时候,init进程都会去读取boot文件,来获取系统要启动那些服务。
如果我们不输入任何参数的话,,默认是其他start_clean.boot文件, 其内容如下:
Read more…
我们知道TCP socket有发送缓冲区和接收缓冲区,这二个缓冲区都可以透过setsockopt设置SO_SNDBUF,SO_RCVBUF来修改,但是这些值设多大呢?这些值和协议栈的内存控制相关的值什么关系呢?
我们来解释下:
$ sysctl net|grep mem
net.core.wmem_max = 131071
net.core.rmem_max = 131071
net.core.wmem_default = 124928
net.core.rmem_default = 124928
net.core.optmem_max = 20480
net.ipv4.igmp_max_memberships = 20
net.ipv4.tcp_mem = 4631520 6175360 9263040
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.udp_mem = 4631520 6175360 9263040
net.ipv4.udp_rmem_min = 4096
net.ipv4.udp_wmem_min = 4096
下面的图很好的解释了上面的问题:
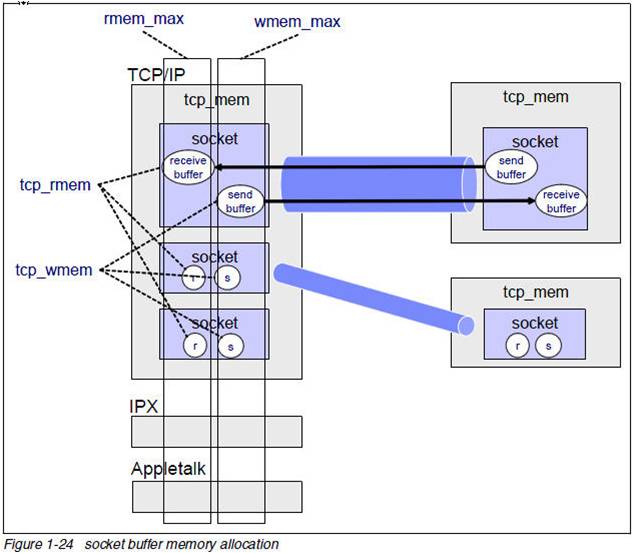
这里要记住的是:TCP协议栈内存是不可交换物理内存,用一字节少一字节。
也正是由于这一点,操作系统出厂的时候上面的默认的内存设置都不算太大。对于一个不是网络密集型的服务器问题不大,但是对于如承担C1M链接的服务器来讲,问题就来了。我们在实践中会发现tcp服务经常超时,有时候超过100ms. 那么这个问题如何定位呢?
Read more…
最近公司在MySQL的数据库上由于采用了高速的如PCIe卡以及大内存,去年在压力测试的时候突然发现数据库的流量可以把一个千M网卡压满了。随着数据库的优化,现在流量可以达到150M,所以我们采用了双网卡,在交换机上绑定,做LB的方式,提高系统的吞吐量。
但是在最近压测试的一个数据库中,mpstat发现其中一个核的CPU被软中断耗尽:
Mysql QPS 2W左右
——– —–load-avg—- —cpu-usage— —swap— -QPS- -TPS- -Hit%-
time | 1m 5m 15m |usr sys idl iow| si so| ins upd del sel iud| lor hit|
13:43:46| 0.00 0.00 0.00| 67 27 3 3| 0 0| 0 0 0 0 0| 0 100.00|
13:43:47| 0.00 0.00 0.00| 30 10 60 0| 0 0| 0 0 0 19281 0| 326839 100.00|
13:43:48| 0.00 0.00 0.00| 28 10 63 0| 0 0| 0 0 0 19083 0| 323377 100.00|
13:43:49| 0.00 0.00 0.00| 28 10 63 0| 0 0| 0 0 0 19482 0| 330185 100.00|
13:43:50| 0.00 0.00 0.00| 26 9 65 0| 0 0| 0 0 0 19379 0| 328575 100.00|
13:43:51| 0.00 0.00 0.00| 27 9 64 0| 0 0| 0 0 0 19723 0| 334378 100.00|
mpstat -P ALL 1说:

针对这个问题,我们利用工具,特别是systemtap, 一步步来调查和解决问题。
Read more…
最近我们为了安全方面的原因,在RDS服务器上做了个代理程序把普通的MYSQL TCP连接变成了SSL链接,在测试的时候,皓庭同学发现Tsung发起了几千个TCP链接后Erlang做的SSL PROXY老是报告gen_tcp:accept返回{error, enfile}错误。针对这个问题,我展开了如下的调查:
首先man accept手册,确定enfile的原因,因为gen_tcp肯定是调用accept系统调用的:
EMFILE The per-process limit of open file descriptors has been reached.
ENFILE The system limit on the total number of open files has been reached.
从文档来看是由于系统的文件句柄数用完了,我们顺着来调查下:
$ uname -r
2.6.18-164.el5
$ cat /proc/sys/fs/file-nr
2040 0 2417338
$ ulimit -n
65535
由于我们微调了系统的文件句柄,具体参考这里 老生常谈: ulimit问题及其影响, 这些参数看起来非常的正常。
先看下net/socket.c代码:
Read more…
Linux下的pipe使用非常广泛, shell本身就大量用pipe来粘合生产者和消费者的. 我们的服务器程序通常会用pipe来做线程间的ipc通讯. 由于unix下的任何东西都是文件,只要是文件,在读取的时候,,就会设置last access time, 所以pipe也不例外., 但是这个时间对我们没有意义 如果pipe使用的非常频繁的时候会碰到由于设置访问时间导致的性能问题. 这个开销远比pipe读写的本身开销大. 相比文件读写的开销, atime微不足道,但是对pipe来讲就不同了.
这个事情是上次和多隆同学在把玩他的网络框架的时候,无意发现的.
我们来分析下pipe的这部分代码:
Read more…
互联网上的TCP服务器面对的环境情况比企业私有的服务器要复杂很多。常见的针对tcp服务器的攻击有以下几种:
1. 伪造协议,导致服务器crash. 比如说某条命令的字段长度,协议最大规定是1024,伪造个4096的。
2. 伪造大的报文,比如说一个包有1024M这么大。
3. 消耗服务器资源。开大量的连接, 以龟速发送报文,比如说每分钟一个字节。
4. DDOS攻击,从不同的IP发起大量的连接, 大流量淹没服务器。
5. 攻击Erlang集群的授权体系,all or nothing。
6. 报文发送顺序逻辑错误,导致服务器crash. 比如说逻辑上应该先发A,再发B, 攻击者调了顺序。
7. 不停的连接断开,消耗服务器对资源的申请和释放,这个通常很耗。
8. 篡改协议中关键时间事件,造成时间混乱。
9. 利用协议中需要大量计算和资源的事件攻击。
10. 利用协议的安全漏洞或者实现系统的漏洞,比如说erlang的atom个数的限制,对系统造成威胁。
11. Hash Collision DoS 等攻击。
12. term_to_binary数据深度太大,底层VM实现用的是c的递归,很容易导致stack overflow。
13. Mnesia数据库各role对等, 很容易在其中一个节点发起数据破坏操作。
14. 大量的请求涌入,导致大量消息产生,消息队列爆了。
15. 利用inets底层实现的漏洞,构造些畸形数据导致inet drv工作异常。
16. 攻击系统的RPC通道,节点间的RPC通道只有一条容易饱和。
17. 攻击系统的NIF实现漏洞,导致VM crash。
等等,有很多方法。
那我们的Erlang版的TCP服务器如何应对这些情况呢?
Read more…
Recent Comments