dropwatch 网络协议栈丢包检查利器
在做网络服务器的时候,会碰到各种各样的网络问题比如说网络超时,通常一般的开发人员对于这种问题最常用的工具当然是tcpdump或者更先进的wireshark来进行抓包分析。通常这个工具能解决大部分的问题,但是比如说wireshark发现丢包,那深层次的原因就很难解释了。这不怪开发人员,要怪就怪linux网络协议栈太深。我们来看下:
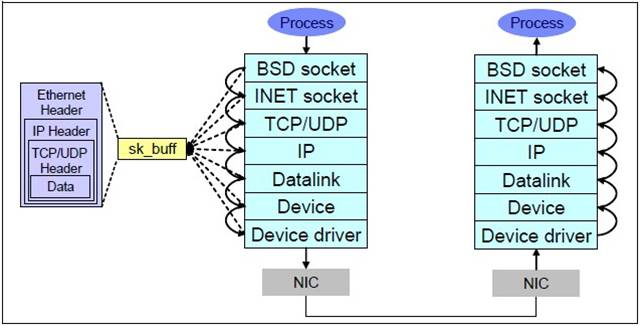
这7层里面每个层都可能由于各种各样的原因,比如说缓冲区满,包非法等,把包丢掉,这样的问题就需要特殊的工具来发现了。 好了,主角dropwatch出场.
它的官方网站在这里
What is Dropwatch
Dropwatch is a project I am tinkering with to improve the visibility developers and sysadmins have into the Linux networking stack. Specifically I am aiming to improve our ability to detect and understand packets that get dropped within the stack.
Dropwatch定位很清晰,就是用来查看协议栈丢包的问题。
RHEL系的系统安装相当简单,yum安装下就好:
$ uname -r
2.6.32-131.21.1.tb477.el6.x86_64
$ sudo yum install dropwatch
man dropwatch下就可以得到使用的帮助,dropwatch支持交互模式, 方便随时启动和停止观测。
使用也是很简单:
$ sudo dropwatch -l kas Initalizing kallsymsa db dropwatch> start Enabling monitoring... Kernel monitoring activated. Issue Ctrl-C to stop monitoring 1 drops at netlink_unicast+251 15 drops at unix_stream_recvmsg+32a 3 drops at unix_stream_connect+1dc
-l kas的意思是获取drop点的符号信息,这样的话针对源码就可以分析出来丢包的地方。
同学们可以参考这篇文章(Using netstat and dropwatch to observe packet loss on Linux servers):http://prefetch.net/blog/index.php/2011/07/11/using-netstat-and-dropwatch-to-observe-packet-loss-on-linux-servers/
那他的原理是什么呢?在解释原理之前,我们先看下这个工具的对等的stap脚本:
Read more…


Recent Comments