前两天微博上的@王关胜同学问了个问题:
#ulimit问题# 关于nproc设置:centos6,内核版本是2.6.32. 默认情况下,ulimit -u的值为1024,是/etc/security/limits.d/90-nproc.conf的值限制;注释掉这个限制后,值为95044;手工设置90-nproc.conf文件,值为新设置的值。想请 问这个95044是怎么来的?
这个问题挺有意思的,这里面有二个信息点:
1. 为什么limit配置文件是 /etc/security/limits.d/90-nproc.conf 而不是其他?
2. 为什么是nproc的值95044,而不是其他。
之前我也写了些ulimit的问题的解决,参见 这里
我们来简单的做下实验:
$ cat /etc/security/limits.d/90-nproc.conf
* soft nproc 8933
$ ulimit -u
8933
$ cat /etc/security/limits.d/90-nproc.conf #注释掉
#* soft nproc 8933
$ ulimit -u
385962
我们可以看出就是说当注释掉限制的话,不同的机器值是不同的。
我们先来回答第一个问题:为什么limit配置文件是 /etc/security/limits.d/90-nproc.conf 而不是其他
这个问题早些时候 杨德华 同学碰到了,也写了篇 博文 来解释redhat6下面如何破解nproc的限制,但是文章没提到这个问题。
Read more…
谷歌近日推出了全新开源压缩算法Zopfli, 官方主页在 这里,相关文档在 这里
Zopfli is a new deflate compatible compressor that was inspired by compression improvements
developed originally for the lossless mode of WebP image compression. Being compatible with
deflate makes Zopfli compatible with zlib and gzip. Most internet browsers support deflate
decompression, and it has a wide range of other applications. This means that Zopflicompatible
decompression is readily widely available.
二个特点:
1. The output produced by Zopfli is 3.7–8.3 % smaller than that of gzip 9.
2. Zopfli is 81 times slower than the fastest measured algorithm gzip 9.
最大的特点是压缩好的数据和zip兼容,也就是说目前标准的zip uncompress算法都能解开,看起来比较适合web服务器的数据存储,降低成本,虽然只有3-8%点的提高,但是数据规模大了,还是很可观的。
下载源码,编译得到zopfli:
$ ./zopfli -h
Usage: zopfli [OPTION]... FILE
-h gives this help
-c write the result on standard output, instead of disk filename + '.gz'
-v verbose mode
--gzip output to gzip format (default)
--deflate output to deflate format instead of gzip
--zlib output to zlib format instead of gzip
--i5 less compression, but faster
--i10 less compression, but faster
--i15 default compression, 15 iterations
--i25 more compression, but slower
--i50 more compression, but slower
--i100 more compression, but slower
--i250 more compression, but slower
--i500 more compression, but slower
--i1000 more compression, but slower
祝玩得开心。
最近关注线上CPU load的人挺多,很多人觉得load太高系统就有问题,就想各种办法来折腾。其实在我看来load只是系统CPU运行队列的在运行进程数的近似值, 如下图:
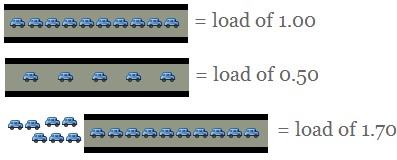
对于Unix发展的初期,机器的性能比较差,CPU核数也少,参考意义比较大。现在的机器都是非常强悍的,CPU,内存,IO各个部件都可以并行运作,这个load相应的就应该和机器的变化相应的变大,我觉得很正常,无需担心,反而应该把注意力放到服务的QPS和RT才是王道。
在微博上讨论了一下午CPU Load,收到非常多的反馈,这里我顺手整理下方便大家:
1. Understanding Linux CPU Load – when should you be worried? 谢谢@nizen靖
参考: 这里 中文版
2. Understanding Linux Load Average 谢谢 @jametong
参考:part1 part2 part3
3. UNIX Load Average 谢谢 @jametong
参考:part1 part2 part3
4. Loadavg问题分析 谢谢 @淘木名、 @淘伯瑜、 @何_登成
参考 这里
小结:群众的力量无穷,很短的时间内挖出这么多有意义的材料。
祝玩得开心!
前段时间看到brendangregg的 Linux Performance Analysis and Tools PPT里面提到Linux常用性能调优工具, 见下图:
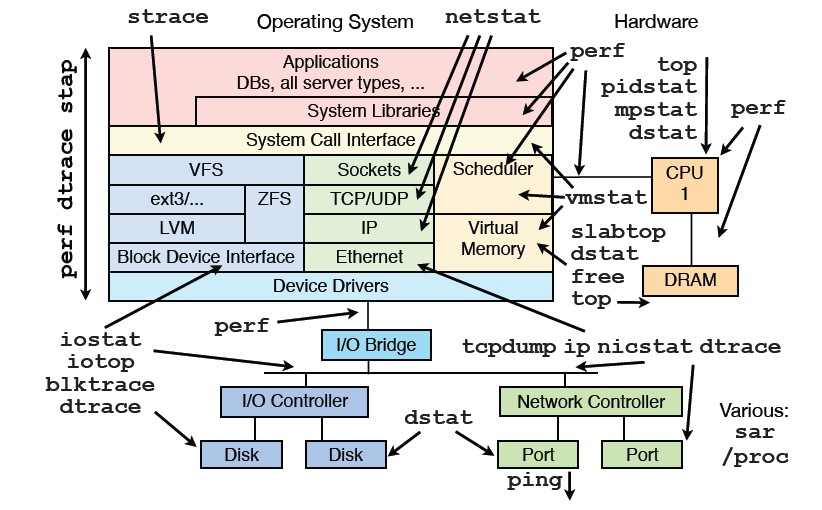
其中提到了的工具,大部分在我日常工具箱里或者在实践的案例里面使用过, 都有很高的价值,这里方便大家索引下:
- nicstat: 参见 这里
- oprofile: 参见 这里
- perf: 参见 这里
- systemtap: 参见 这里
- iotop: 参见 这里
- blktrace: 参见 这里
- dstat: 参见 这里
- strace: 参见 这里
- pidstat: 参见 这里
- vmstat: 参见 这里
- slabtop: 参见 这里
- tcpdump: 参见 这里
- free: 参见 这里
- mpstat: 参见 这里
- netstat: 参见 这里
- tcprstat: 参见 这里
更多的Linux系统工具介绍请参见 这里
祝玩得开心!
前段时间看到brendangregg的 Linux Performance Analysis and Tools PPT里面提到的nicstat,研究了下是个不错的东西,分享给大家。
nicstat is to network interfaces as “iostat” is to disks, or “prstat” is to processes.
nicstat原本是Solaris平台下显示网卡流量的工具,Tim Cook将它移植到linux平台,官方网站见 这里。 相比netstat, 他有以下关键特性:
- Reports bytes in & out as well as packets.
- Normalizes these values to per-second rates.
- Reports on all interfaces (while iterating)
- Reports Utilization (rough calculation as of now)
- Reports Saturation (also rough)
- Prefixes statistics with the current time
我们来体验下,首先安装之,源码在 这里 下, 目前最新的版本是1.92。
解开后,由于这个版本默认是在32位linux下编译,所以需要改下Makefile.Linux:
$ uname -r
2.6.32-131.21.1.tb477.el6.x86_64
$ diff Makefile.Linux64 Makefile.Linux
17c17
< CFLAGS = $(COPT) -m32
---
> CFLAGS = $(COPT)
$ sudo make -f Makefile.Linux install
sudo install -o root -g root -m 4511 `./nicstat.sh --bin-name` /usr/local/bin/nicstat
sudo install -o bin -g bin -m 555 enicstat /usr/local/bin
sudo install -o bin -g bin -m 444 nicstat.1 /usr/local/share/man/man1/nicstat.1
enicstat就安装好可以使用了。
使用文档在这里: man nicstat
由于在linux下需要获取网卡的speed等信息,需要以特权用户运行。
Read more…
我们知道TCP socket有发送缓冲区和接收缓冲区,这二个缓冲区都可以透过setsockopt设置SO_SNDBUF,SO_RCVBUF来修改,但是这些值设多大呢?这些值和协议栈的内存控制相关的值什么关系呢?
我们来解释下:
$ sysctl net|grep mem
net.core.wmem_max = 131071
net.core.rmem_max = 131071
net.core.wmem_default = 124928
net.core.rmem_default = 124928
net.core.optmem_max = 20480
net.ipv4.igmp_max_memberships = 20
net.ipv4.tcp_mem = 4631520 6175360 9263040
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.udp_mem = 4631520 6175360 9263040
net.ipv4.udp_rmem_min = 4096
net.ipv4.udp_wmem_min = 4096
下面的图很好的解释了上面的问题:
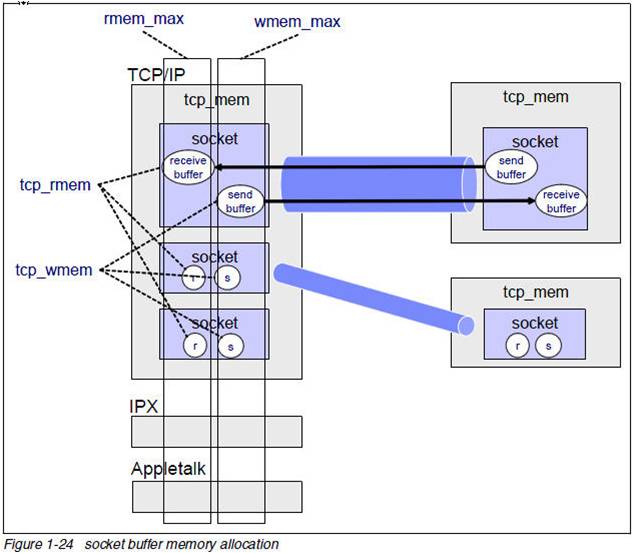
这里要记住的是:TCP协议栈内存是不可交换物理内存,用一字节少一字节。
也正是由于这一点,操作系统出厂的时候上面的默认的内存设置都不算太大。对于一个不是网络密集型的服务器问题不大,但是对于如承担C1M链接的服务器来讲,问题就来了。我们在实践中会发现tcp服务经常超时,有时候超过100ms. 那么这个问题如何定位呢?
Read more…
Recent Comments