喝杯黑咖啡时间
dropwatch 网络协议栈丢包检查利器
February 25th, 2013
13 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: dropwatch 网络协议栈丢包检查利器
在做网络服务器的时候,会碰到各种各样的网络问题比如说网络超时,通常一般的开发人员对于这种问题最常用的工具当然是tcpdump或者更先进的wireshark来进行抓包分析。通常这个工具能解决大部分的问题,但是比如说wireshark发现丢包,那深层次的原因就很难解释了。这不怪开发人员,要怪就怪linux网络协议栈太深。我们来看下:
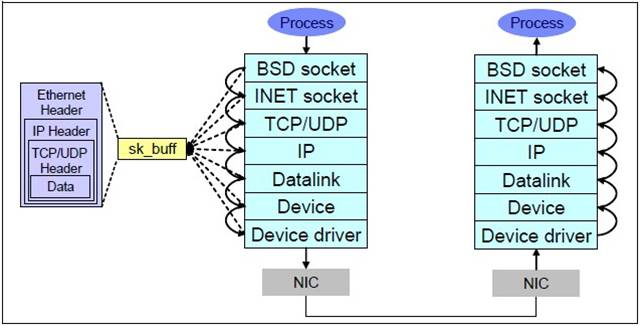
这7层里面每个层都可能由于各种各样的原因,比如说缓冲区满,包非法等,把包丢掉,这样的问题就需要特殊的工具来发现了。 好了,主角dropwatch出场.
它的官方网站在这里
What is Dropwatch
Dropwatch is a project I am tinkering with to improve the visibility developers and sysadmins have into the Linux networking stack. Specifically I am aiming to improve our ability to detect and understand packets that get dropped within the stack.
Dropwatch定位很清晰,就是用来查看协议栈丢包的问题。
RHEL系的系统安装相当简单,yum安装下就好:
$ uname -r
2.6.32-131.21.1.tb477.el6.x86_64
$ sudo yum install dropwatch
man dropwatch下就可以得到使用的帮助,dropwatch支持交互模式, 方便随时启动和停止观测。
使用也是很简单:
$ sudo dropwatch -l kas Initalizing kallsymsa db dropwatch> start Enabling monitoring... Kernel monitoring activated. Issue Ctrl-C to stop monitoring 1 drops at netlink_unicast+251 15 drops at unix_stream_recvmsg+32a 3 drops at unix_stream_connect+1dc
-l kas的意思是获取drop点的符号信息,这样的话针对源码就可以分析出来丢包的地方。
同学们可以参考这篇文章(Using netstat and dropwatch to observe packet loss on Linux servers):http://prefetch.net/blog/index.php/2011/07/11/using-netstat-and-dropwatch-to-observe-packet-loss-on-linux-servers/
那他的原理是什么呢?在解释原理之前,我们先看下这个工具的对等的stap脚本:
Read more…
Post Footer automatically generated by wp-posturl plugin for wordpress.
mmap的MAP_POPULATE标志妙用
January 19th, 2013
1 comment
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: mmap的MAP_POPULATE标志妙用
前段时间在学习MySQL和内核的时候,碰巧遇到twitter的dba老大在折腾numa不平衡问题的问题而写了二篇numa相关的文章,非常有技术含量。参见 这里
numa不平衡问题的解决方案摘抄如下:
A more thorough solution
The original post also only addressed only one part of the solution: using interleaved allocation.
A complete and reliable solution actually requires three things, as we found when implementing this change for production systems at Twitter:1. Forcing interleaved allocation with numactl –interleave=all. This is exactly as described previously, and works well.
2. Flushing Linux’s buffer caches just before mysqld startup with sysctl -q -w vm.drop_caches=3. This helps to ensure allocation fairness, even if the daemon is
restarted while significant amounts of data are in the operating system buffer cache.3. Forcing the OS to allocate InnoDB’s buffer pool immediately upon startup, using MAP_POPULATE where supported (Linux 2.6.23+), and falling back to memset otherwise. This forces the NUMA node allocation decisions to be made immediately, while the buffer cache is still clean from the above flush.
具体的代码实现参看 这里
其中就提到了如何用mmap的MAP_POPULATE来达到匿名页预先分配的问题,这是非常好的思路。
我们来man mmap看下:
MAP_POPULATE (since Linux 2.5.46)
Populate (prefault) page tables for a mapping. For a file mapping, this causes read-ahead on
the file. Later accesses to the mapping will not be blocked by page faults. MAP_POPULATE is
only supported for private mappings since Linux 2.6.23.
这个标志很早就有了,但是其实很少程序用到了这个特性,去年分析内核内存系统实现的时候,重点读过这块代码。这个特性在特殊的场景下还是挺有好处的。
我们知道通常我们mmap出来的内存,要不是匿名页面,要不就是文件的映射。当访问这块线性地址的时候,如果需要的页面不在内存中,就会发生缺页中断,内核分配物理内存,如果是文件后背的话,顺手把文件读进来。这样在高性能服务器里面分配内存的动作就会成为问题。
问题主要体现在2点:
1. 内存分配的时候,系统的内存已经比较乱了,不知道系统会从那个numa节点去分配,而且极端的时候,发生内存短缺,会换出内存页面,这个时间非常不可控。内存的分配也无法准确的指定。
2. 读文件这个时间非常不可控,系统可能会被挂起等待IO动作完成。
如果我们能够在系统内存还比较干净的时候,比如刚开机或者刚做完vm.drop_caches=3的时候,去把我们需要的内存或者数据预先按照我们设想的方式来准备,虽然这个集中化的动作会化很长的时间,但是换来的是后续的可控性。
mmap的MAP_POPULATE标志使用代码参见这里:
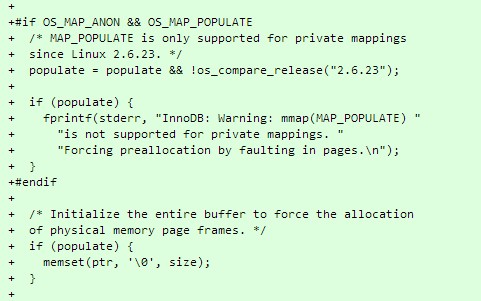
如果你的系统没有这个函数,使用memset(ptr, ‘\0’, size);也是个好的方案。
总结:高性能服务器细节多,技术含量高!
祝玩的开心!
Post Footer automatically generated by wp-posturl plugin for wordpress.
Linux Used内存到底哪里去了?
January 19th, 2013
44 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: Linux Used内存到底哪里去了?
前几天 纯上 同学问了一个问题:
我ps aux看到的RSS内存只有不到30M,但是free看到内存却已经使用了7,8G了,已经开始swap了,请问ps aux的实际物理内存统计是不是漏了哪些内存没算?我有什么办法确定free中used的内存都去哪儿了呢?
这个问题不止一个同学遇到过了,之前子嘉同学也遇到这个问题,内存的计算总是一个迷糊账。 我们今天来把它算个清楚下!
通常我们是这样看内存的剩余情况的:
$free -m
total used free shared buffers cached
Mem: 48262 7913 40349 0 14 267
-/+ buffers/cache: 7631 40631
Swap: 2047 336 1711
那么这个信息是如何解读的呢,以下这个图解释的挺清楚的!
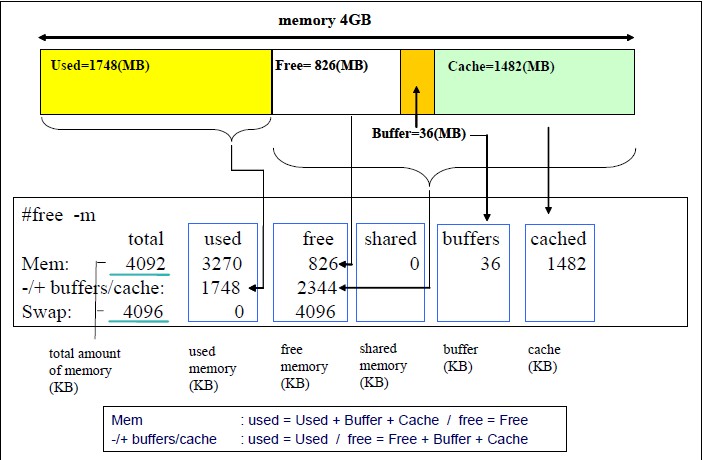
补充(不少人反映图不清晰,请参考:http://www.redbooks.ibm.com/redpapers/pdfs/redp4285.pdf P46-47)
上面的情况下我们总的内存有48262M,用掉了7913M。 其中buffer+cache总共14+267=281M, 由于这种类型的内存是可以回收的,虽然我们用掉了7913M,但是实际上我们如果实在需要的话,这部分buffer/cache内存是可以放出来的。
我们来演示下:
$ sudo sysctl vm.drop_caches=3
vm.drop_caches = 3
$ free -m
total used free shared buffers cached
Mem: 48262 7676 40586 0 3 41
-/+ buffers/cache: 7631 40631
Swap: 2047 336 1711
我们把buffer/cache大部分都清除干净了,只用了44M,所以我们这次used的空间是7676M。
到现在我们比较清楚几个概念:
1. 总的内存多少
2. buffer/cache内存可以释放的。
3. used的内存的概率。
即使是这样我们还是要继续追查下used的空间(7637M)到底用到哪里去了?
Read more…
Post Footer automatically generated by wp-posturl plugin for wordpress.
深度剖析告诉你irqbalance有用吗?
January 17th, 2013
8 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: 深度剖析告诉你irqbalance有用吗?
irqbalance项目的主页在这里
irqbalance用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode。处于Performance mode 时,irqbalance 会将中断尽可能均匀地分发给各个 CPU core,以充分利用 CPU 多核,提升性能。
处于Power-save mode 时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗。
在RHEL发行版里这个守护程序默认是开机启用的,那如何确认它的状态呢?
# service irqbalance status
irqbalance (pid PID) is running…
然后在实践中,我们的专用的应用程序通常是绑定在特定的CPU上的,所以其实不可不需要它。如果已经被打开了,我们可以用下面的命令关闭它:
# service irqbalance stop
Stopping irqbalance: [ OK ]
或者干脆取消开机启动:
# chkconfig irqbalance off
下面我们来分析下这个irqbalance的工作原理,好准确的知道什么时候该用它,什么时候不用它。
既然irqbalance用于优化中断分配,首先我们从中断讲起,文章很长,深吸一口气,来吧!
SMP IRQ Affinity 相关东西可以参见 这篇文章
摘抄重点:
SMP affinity is controlled by manipulating files in the /proc/irq/ directory.
In /proc/irq/ are directories that correspond to the IRQs present on your
system (not all IRQs may be available). In each of these directories is
the “smp_affinity” file, and this is where we will work our magic.
说白了就是往/proc/irq/N/smp_affinity文件写入你希望的亲缘的CPU的mask码! 关于如何手工设置中断亲缘性,请参见我之前的博文: 这里 这里
接着普及下概念,我们再来看下CPU的拓扑结构,首先看下Intel CPU的各个部件之间的关系:
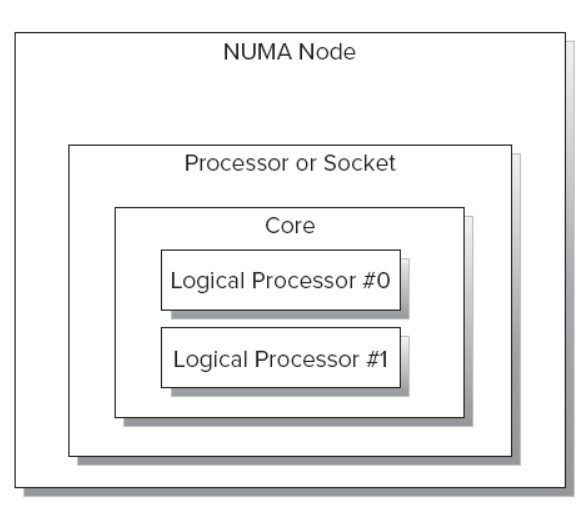
一个NUMA node包括一个或者多个Socket,以及与之相连的local memory。一个多核的Socket有多个Core。如果CPU支持HT,OS还会把这个Core看成 2个Logical Processor。
Read more…
Post Footer automatically generated by wp-posturl plugin for wordpress.
Likwid-高性能服务器开发不可缺少的工具箱
January 16th, 2013
8 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: Likwid-高性能服务器开发不可缺少的工具箱
做高性能服务器的时候,知道如何开发高性能代码是一个事情,开发出来的系统是不是高性能那就是另外一个事情了。
通常我们需要了解系统的CPU拓扑结构,内存使用情况,各种CPU性能计数器的数字,各种CPU Cache的使用情况,命中率等等信息,这些信息有效的结合在一起才能准确的分析出我们程序的缺陷,从而找到更好的优化点。 通常这些信息是散落在系统的各个地方,对于普通的开发人员很难汇总起来,形成合力。
好了,以精细出名的德国人又来帮忙了,隆重推出Likwid。

Likwid项目的地址在这里。 根据主页的上的描述:
Likwid stands for Like I knew what I am doing. This project contributes easy to use command line tools for Linux to support programmers in developing high performance multi threaded programs.
It contains the following tools:
likwid-topology: Show the thread and cache topology
likwid-perfctr: Measure hardware performance counters on Intel and AMD processors
likwid-features: Show and Toggle hardware prefetch control bits on Intel Core 2 processors
likwid-pin: Pin your threaded application without touching your code (supports pthreads, Intel OpenMP and gcc OpenMP)
likwid-bench: Benchmarking framework allowing rapid prototyping of threaded assembly kernels
likwid-mpirun: Script enabling simple and flexible pinning of MPI and MPI/threaded hybrid applications
likwid-perfscope: Frontend for likwid-perfctr timeline mode. Allows live plotting of performance metrics.
likwid-powermeter: Tool for accessing RAPL counters and query Turbo mode steps on Intel processor.
likwid-memsweeper: Tool to cleanup ccNUMA memory domains.
Likwid stands out because:No kernel patching, any vanilla linux 2.6 or newer kernel works
Transparent, always clear which events are chosen, event tags have the same naming as in documentation
Lightweight, LIKWID tries to add no overhead and keeps out of your way.
Easy to use, simple to build, no need to touch your code, configurable from outside. Clear CLI interface.
Multiplatform, likwid supports Intel and AMD processors
Up to date, likwid tries to fully support new processors as soon as possible
Extensible, you can add functionality by means of simple text files
同时他的文档还是做的非常不错的,使用的介绍在这里
具体的使用我就不墨迹了,文档里面都有。我在这里秀下他的功能:
Read more…
Post Footer automatically generated by wp-posturl plugin for wordpress.
为什么Erlang是软实时的
January 16th, 2013
6 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: 为什么Erlang是软实时的
之前在微博上@老师木 同学发起了个关于Erlang抢占式调度的讨论,相对于其他语言Erlang是真正的抢占式调度服务,这也是erlang能够号称软实时的很重要的原因之一,另外二个原因分别是erlang的GC是针对每个进程的,每次GC通常只需要收集几K或者几十个对象;BIF是用trap机制来保证公平的。
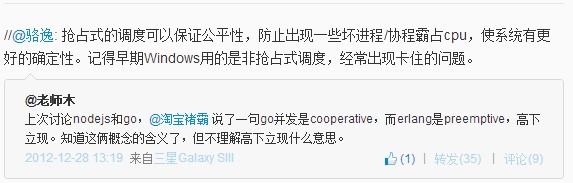
今天在微博上看到erlang调度器的工作细节的文章来源见这里。这篇文章很准确的描述了Erlang调度器是如何工作的,很好的澄清了大家对各种语言调度器的误解。 本来我前段时间想自己写,看来没必要了,就顺手贴出来给大家。
How Erlang does scheduling
In this, I describe why Erlang is different from most other language runtimes. I also describe why it often forgoes throughput for lower latency.
TL;DR – Erlang is different from most other language runtimes in that it targets different values. This describes why it often seem to perform worse if you have few processes, but well if you have many.
From time to time the question of Erlang scheduling gets asked by different people. While this is an abridged version of the real thing, it can act as a way to describe how Erlang operates its processes. Do note that I am taking Erlang R15 as the base point here. If you are a reader from the future, things might have changed quite a lot—though it is usually fair to assume things only got better, in Erlang and other systems.
Read more…
Post Footer automatically generated by wp-posturl plugin for wordpress.
PCI-E SSD卡中断配置问题
January 15th, 2013
9 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: PCI-E SSD卡中断配置问题
随着PCI-E SSD卡的普及,很多高性能的服务器都用上了如fusionio这样的设备来提升IO的性能,这样会带来一些问题。 这些高速的IO设备在运作的时候会产生大量的中断来通知IO的完成,全速运转的系统上中断达到14000irqs/sec 如图:
![]()
而中断是默认摊到所有的CPU:
#cat /proc/irq/1/smp_affinity
ffffffff
在实践中来看会落在最繁忙的0核心上,这样就会给性能雪上加霜,效果如下:
cat /proc/interrupts |grep fct
144: 39913474 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR-PCI-MSI-edge iodrive-fct0
145: 44976079 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR-PCI-MSI-edge iodrive-fct1
中断144,145属于iodrive-fct高速设备的,都落在了0号核心上。
对于大多数的高性能服务器通常都有16-32个核心,越靠后面的核心越闲,那为什么我们不把中断移到后面的核心,让核心0解放出来多做其他的事情呢?毕竟由于历史原因,很多东西还是在核心0上做的,减负!
这个问题的核心就是要设置/proc/N/145/smp_affinity的CPU掩码, 手工做比较麻烦。
好了,脚本来了:
# cat set_fio_affinity.sh
#!/bin/bash
set_affinity()
{
MASK_TMP=$((1<<(`expr $VEC + $CORE`)))
MASK=`printf "%X" $MASK_TMP`
printf "%s mask=%s for /proc/irq/%d/smp_affinity\n" $DEV$VEC $MASK $IRQ
printf "%s" $MASK > /proc/irq/$IRQ/smp_affinity
}
if [ $# -ne 1 ] ; then
echo "usage:"
echo " $0 core "
exit
fi
CORE=$1
DEV="iodrive-fct"
MAX=`grep -i $DEV /proc/interrupts | wc -l`
if [ "$MAX" == "0" ] ; then
echo no $DIR vectors found on $DEV
exit
fi
for VEC in `seq 0 1 $MAX`
do
for IRQ in `cat /proc/interrupts | grep -i $DEV$VEC|cut -d: -f1| sed "s/ //g"`
do
set_affinity
done
done
# ./set_fio_affinity.sh 30
iodrive-fct0 mask=40000000 for /proc/irq/144/smp_affinity
iodrive-fct1 mask=80000000 for /proc/irq/145/smp_affinity
再cat /proc/interrupts看下实践效果就可以看到后面的核心已经有中断了,而且0号核心上的数字没变!

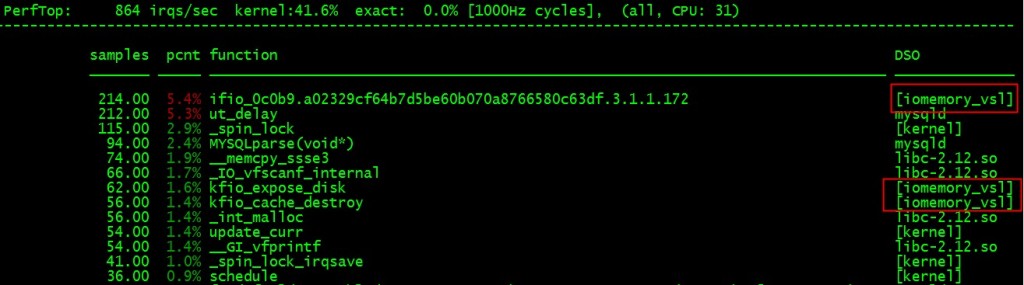
# perf top –cpu=31
也验证了这一点:
另外一姐妹篇 “MYSQL数据库网卡软中断不平衡问题及解决方案” 参见 这里!
祝玩的开心!
Post Footer automatically generated by wp-posturl plugin for wordpress.
Recent Comments