Erlang的调度器效率非常高,大概在128核的情况下有80%的利用率,即使是这样,由于CPU和内存体系的结构的限制,调度器的实现还是有大量的锁存在。erts的实现为了避免core scale的问题,通常不会采用锁在那里傻等,而是采用更乐观的无锁算法,这样会有不少的CPU空转现象。
那么如何评估调度器的效率呢?我们可以从系统层面,比如从top看,每个调度器线程忙不忙。但是这只是表象,调度器可能在空转等锁,最靠谱的应该是把调度器真正干活的时间累计起来,比较真实的反应它的效率。
erlang从R15以后提供了调度器的利用率调查,这个函数就是:erlang:statistics(scheduler_wall_time) 。
我们来看下它的文档:
statistics(Item :: scheduler_wall_time) ->
[{SchedulerId, ActiveTime, TotalTime}] | undefined
Types:
SchedulerId = integer() >= 1
ActiveTime = TotalTime = integer() >= 0
Returns a list of tuples with {SchedulerId, ActiveTime, TotalTime}, where SchedulerId is an integer id of the scheduler, ActiveTime is the duration the scheduler has been busy, TotalTime is the total time duration since scheduler_wall_time activation. The time unit is not defined and may be subject to change between releases, operating systems and system restarts. scheduler_wall_time should only be used to calculate relative values for scheduler-utilization. ActiveTime can never exceed TotalTime.
The definition of a busy scheduler is when it is not idle or not scheduling (selecting) a process or port, meaning; executing process code, executing linked-in-driver or NIF code, executing built-in-functions or any other runtime handling, garbage collecting or handling any other memory management. Note, a scheduler may also be busy even if the operating system has scheduled out the scheduler thread.
Returns undefined if the system flag scheduler_wall_time is turned off.
The list of scheduler information is unsorted and may appear in different order between calls.
Using scheduler_wall_time to calculate scheduler utilization.
> erlang:system_flag(scheduler_wall_time, true).
false
> Ts0 = lists:sort(erlang:statistics(scheduler_wall_time)), ok.
ok
Some time later we will take another snapshot and calculate scheduler-utilization per scheduler.
> Ts1 = lists:sort(erlang:statistics(scheduler_wall_time)), ok.
ok
> lists:map(fun({{I, A0, T0}, {I, A1, T1}}) ->
{I, (A1 – A0)/(T1 – T0)} end, lists:zip(Ts0,Ts1)).
[{1,0.9743474730177548},
{2,0.9744843782751444},
{3,0.9995902361669045},
{4,0.9738012596572161},
{5,0.9717956667018103},
{6,0.9739235846420741},
{7,0.973237033077876},
{8,0.9741297293248656}]
Using the same snapshots to calculate a total scheduler-utilization.
> {A, T} = lists:foldl(fun({{_, A0, T0}, {_, A1, T1}}, {Ai,Ti}) ->
{Ai + (A1 – A0), Ti + (T1 – T0)} end, {0, 0}, lists:zip(Ts0,Ts1)), A/T.
0.9769136803764825
其中要注意的是”scheduler_wall_time is by default disabled. Use erlang:system_flag(scheduler_wall_time, true) to enable it.”。原因是运行期需要去做统计工作会影响性能。而且函数返回的每个调度器的使用情况顺序是乱的,需要排序下。
percept2提供了个percept2_sampling来帮我们可视化这个利用率, 演示如下:
我们启动percept2_sampling收集系统一分钟的数据,然后用web界面查看:
$ erl -pa percept2/ebin
Erlang R15B03 (erts-5.9.3.1) [source] [64-bit] [smp:16:16] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.9.3.1 (abort with ^G)
1> percept2:start_webserver(8933).
{started,"rds064076",8933}
2> percept2_sampling:start([all], 60000, ".").
<0.57.0>
它的操作界面如下:
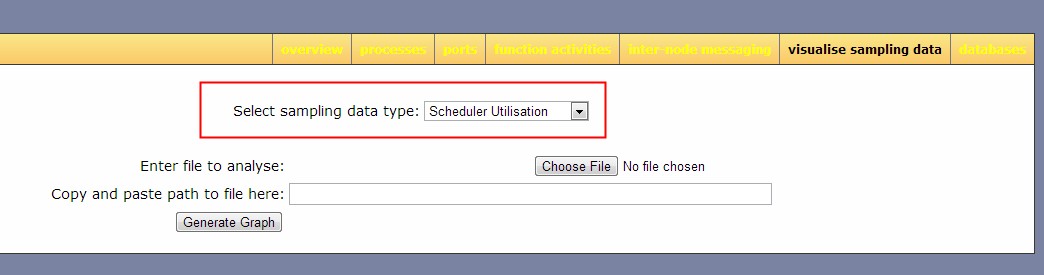
调度器的利用率效果如图:
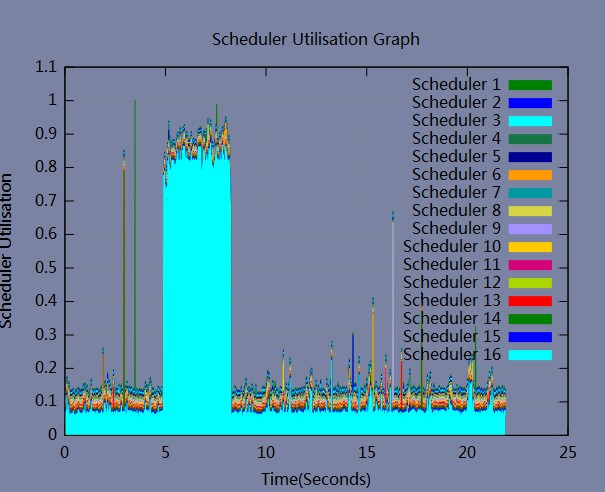
我们可以看到3号调度器比较忙,其他的都闲的。
祝玩得开心!

Recent Comments