喝杯黑咖啡时间
Erlang内存分配器之mbcs_pool
April 27th, 2014
1 comment
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: Erlang内存分配器之mbcs_pool
Erlang R17.0 发布的release note 里面花了挺多笔墨讲了内存carrier迁移的特性:
Support for migration of memory carriers between memory allocator instances has been introduced.
By default this feature is not enabled and do not effect the characteristics of the system. When enabled it has the following impact on the characteristics of the system:* Reduced memory footprint when the memory load is unevenly distributed between scheduler specific allocator instances.
* Depending on the default allocaton strategy used on a specific allocator there might or might not be a slight performance loss.
* When enabled on the fix_alloc allocator, a different strategy for management of fix blocks will be used.
* The information returned from erlang:system_info({allocator, A}), and erlang:system_info({allocator_sizes, A}) will be slightly different when this feature has been enabled. An mbcs_pool tuple will be present giving information about abandoned carriers, and in the fix_alloc case no fix_types tuple will be present.For more information, see the documentation of the +M acul command line argument.
那么什么是”migration of memory carriers between memory allocator instances“,解决什么问题呢?
官方的文档 erts/emulator/internal_doc/CarrierMigration.md, 见这里, 已经描述的非常清楚了。
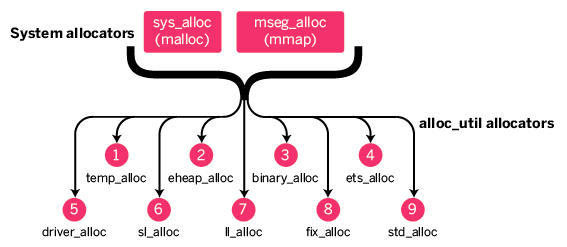
我来简单的说下复述下:
Erlang的内存分配器为了提高性能,每个调度器一个都有自己的内存池,在申请/释放内存的可以避免大量的锁争用,提高了性能。但也带来内存浪费的问题,首先调度器默认使用策略是“full load or not”, 也就是说低ID的调度器如果没饱和的话,不会用下一个调度器。在高负载的情况下,更多的调度器被启用,该调度器上的内存被缓冲,留在池子里。当工作负载下去的的话,因为压力没到,高ID的调度器没机会被使用,也就是说这个时候,这个调度器上的内存就浪费掉了,从整个VM的角度来看,内存的碎片率就很高。Erlang的VM是以稳定性著名的,但是它也有Crash的时候,十有八九是因为内存爆了。我们在设计系统的时候,通常从数据量去反推需要的内存,但是如果有碎片或者浪费存在严重的话,我们就无法准确,就可能导致灾难。 为了解决这个问题,最直接的反应就是当每个调度器池子里面的内存使用率低于一定程度的时候,就把该块内存出让出来,让有需要的调度器能够利用起来。这就是内存carriers迁移要解决的核心问题。
这个特性在R16加入的默认不启用,R17默认启用了,也就是说+M acul 默认是“de”. 带来的影响有下面几个:
1. 内存申请的效率,现在的测试是先在自己的池子里面分配,不满足了就找cpool,再不满足才去找mseg或者sys分配器申请。效率和利用率是鱼和熊掌不可兼得。
2. 内存分配器的内存除了在池子里面还有在cpool里,统计内存的时候要小心。
3. 内存浪费率到什么时候被废弃。
Post Footer automatically generated by wp-posturl plugin for wordpress.
基于LLVM的高性能Erlang(Hipe)尝鲜
March 25th, 2014
11 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: 基于LLVM的高性能Erlang(Hipe)尝鲜
即将发布的R17A版本引入很重要的一个针对性能提升的特性:”Support the LLVM backend in HiPE”,具体改变参见这里. 我们知道Erlang是一门领域语言,第一天就是为电信工业高可用,集群和热更新环境而设计的,语言的性能一开始不是重点。直到R12版本才加入SMP多处理器,充分适应多核化的硬件发展趋势,从此向着高性能大步迈进。
Erlang的虚拟机是register based的,性能上和python类似,和c语言大概有7倍的差距。虽然大部分的集群和网络服务器,性能瓶颈在IO上面,而且这块erts(erlang运行期系统)做的非常的强大,但是一旦涉及到大量的计算,就有点麻烦了,因为它缺乏类似java jit那样强大的支持,让语言足够的快。解决方案是自己写nif、driver或者bif,但是会破坏稳定性。
它很早有自己的hipe, 主要是Uppsala University大学的Kostis Sagonas带领学生做的, 97年开始做的,性能的提升虽然不少,但是在架构上有些缺点,而且和otp团队是二个不同的团队,在稳定性上无法达到产品质量。为了进一步解决这个问题,他带着Christos Stavrakakis和Yiannis Tsiouris,重新实现了基于LLVM后端的Hipe,也就是erllvm,官方网站在这里.
官方描述如下:
ErLLVM is a project aiming at providing multiple back ends for the High Performance Erlang (HiPE) with the use of the LLVM infastructure.
这次R17发布就是把ErLLVM融入到erlang主干版本去。那么ErLLVM的技术改进点在哪里?看下面的图就明白了。
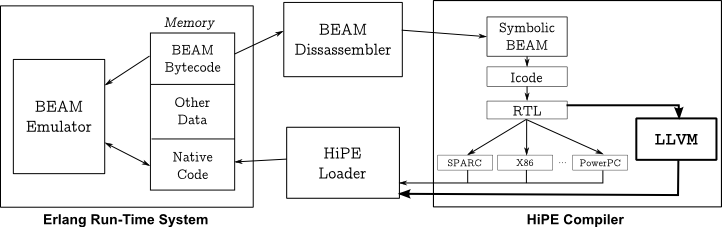
最关键的一点就是之前的hipe自己从RTL生成硬件代码,而ErlLvm把这个事情交给了llvm专业去生成,它只做RTL->llvm层的薄薄的翻译,这样稳定性的问题就offload交给了llvm,而llvm的稳定性是经过社区规模考验的。

这样就很好的解决了稳定性和性能的问题。 Read more…
Post Footer automatically generated by wp-posturl plugin for wordpress.
Erlang 新数据类型Map的定位和性能
March 12th, 2014
4 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: Erlang 新数据类型Map的定位和性能
Erlang R17最大的语言层面的变化莫过是引入 Map数据结构,参见:Erlang R17新特性浅评 还有 这里。
Map相关的细节在EEP 43上,参见 这里。
定位:
A record replacement is just that, a replacement. It’s like asking the question, “What do we have?” instead of “What can we get?” The instant rebuttal would be “What do we need?” I say Maps.
满足的约束:
The new data-type shall have semantics, syntax and operations that:
> provides an association set from key terms to value terms which can be constructed, accessed and updated using language syntax
> can be uniquely distinguished from every other data-type in the language
> has no compile-time dependency for constructing, accessing or updating contents of maps nor for passing maps between modules, processes or over Erlang distribution
> can be used in matching expressions in the language
> has a one-to-one association between printing and parsing the data-type
> has a well defined order between terms of the type and other Erlang types
> has at most O(log N) time complexity in insert and lookup operations, where N is the number of key-value associations.
思遥同学很贴心的写了一篇maps的分析,参看 Erlang 的新数据结构 map 浅析
Post Footer automatically generated by wp-posturl plugin for wordpress.
cowboy-高性能简洁的erlang版web框架
February 27th, 2014
4 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: cowboy-高性能简洁的erlang版web框架
大部分的分布式系统只要有业务价值,必须提供如API,监控,管理界面等等,而http是目前事实上的标准,换句话说分布式系统必须提供强大的web框架,编写业务才能容易上手。 Erlang系统第一天就是设计干这个的,自然有很多web框架,出名的如mochiweb, cowboy,chicagoboss, misultin,inets等框架,竞争也是非常激烈。今天我要推荐的是新秀:cowboy,项目在这里
那么Cowboy是什么呢?
Cowboy is a small, fast and modular HTTP server written in Erlang.
其定位非常明确:
Cowboy aims to provide a complete HTTP stack in a small code base. It is optimized for low latency and low memory usage, in part because it uses binary strings.
Cowboy provides routing capabilities, selectively dispatching requests to handlers written in Erlang.
Because it uses Ranch for managing connections, Cowboy can easily be embedded in any other application.
No parameterized module. No process dictionary. Clean Erlang code.
目前还支持websocket和spdy协议(由leofs赞助),是个完整的http协议栈实现,功能强劲。由于是最近才发展起来的,充分考虑了性能,强调代码的整洁,作者在产品层面对erlang的优缺点非常了解,实现的很优雅很高效。 目前多个项目都是用它支撑的,也反过来刺激它走的很稳很快,代码维护也很活跃,比如竞争对手misultin感觉没有超越的希望就放弃了。
Misultin development has been discontinued.
There currently are three main webserver libraries which basically do similar things:
* Mochiweb
* Cowboy
* Misultin
Mochiweb has been around the block for a while and it’s proven solid in production, I can only recommend it for all basic webserver needs you might have. Cowboy has a very interesting approach since it allows to use multiple TCP and UDP protocols on top of a common acceptor pool. It is a very modern approach, is very actively maintained and many projects are starting to be built around it.
在c实现中nginx是做的最好的,但是如果你用nginx写自己的业务代码的时候,你就会把整个系统的性能拖到实现者的水平,总体来讲性能不会太高。而基于cowboy的实现再加上erlang天然的优势,通常一台机器做到几万的QPS的业务,对实现者的要求非常低,可以大大促进生产力,额外的福利还有热升级和稳定可靠。
小结:技术在进步,思想也要放开。
祝玩的开心。
Post Footer automatically generated by wp-posturl plugin for wordpress.
Recon-Erlang线上系统诊断工具
February 27th, 2014
6 comments
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: Recon-Erlang线上系统诊断工具
Erlang系统素以稳定可靠闻名,但是它也是c实现的,也是要管理比如内存,锁等等复杂的事情,也会出现Crash,而且crash的时候大部分原因是因为内存问题。为此erlang运行期提供了强大的自省机制,帮忙用户诊断问题。自省机制过于强大,而且大部分的信息是散落在各处的,不是太资深的用户很难总体把握,而且线上系统读取这些信息的时候,也要考虑对系统的影响。 这时候recon来帮忙了, 源码在这里。
Recon的定位很清晰:
Recon wants to be a set of tools usable in production to diagnose Erlang problems or inspect production environment safely.
它的作者Ferd就是 Learn You Some Erlang for great good! 书的作者(中文版我在翻译)参见:http://learnyousomeerlang.com/
Ferd同学素以讲解事情深入简出为最大特点,思路特别清晰,目前就职于Heroku, 负责开发logplex项目,而Recon就是在运维logplex时候吃自己狗粮的时候的产物,参见这篇文章的描述,非常有技术含量的分析,特别的分析了erlang内存分配器的工作原理,如何观察,提高内存分配率。
回到Recon, 它的文档非常清晰,见这里。
Recon主要包括三个模块:
recon
Main module, contains basic functionality to interact with the recon application. It includes functions to gather information about processes and the general state of the virtual machine, ports, and OTP behaviours running in the node. It also includes a few functions to facilitate RPC calls with distributed Erlang nodes.recon_lib
Regroups useful functionality used by recon when dealing with data from the node. Would be an interesting place to look if you were looking to extend Recon’s functionalityrecon_alloc
Regroups functions to deal with Erlang’s memory allocators, or particularly, to try to present the allocator data in a way that makes it simpler to discover the presence of possible problems.
和一系列脚本用于在发生crashdump的时候帮助用户分析到原因, 设计的时候充分考虑到了对系统的最小影响,在线上使用是很安全的。
其中最有价值的是 recon_alloc, 基本上把内存分配器的细节和复杂都屏蔽起来,用户可以很好的看到内存工作的效率.
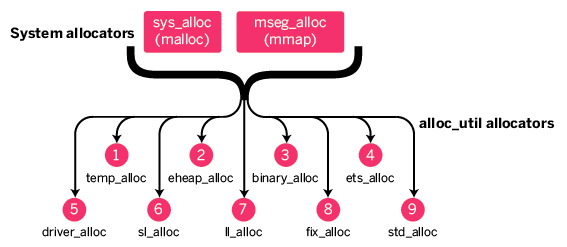
借助recon_alloc发现了很多线上内存分配器利用率过低的问题。
祝玩得开心!
注: Recon新版本Provides production-safe tracing facilities, to dig into the execution of programs and function calls as they are running. 参见 这里
Post Footer automatically generated by wp-posturl plugin for wordpress.
Erlang R17新特性浅评
February 26th, 2014
1 comment
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: Erlang R17新特性浅评
Erlang R17RC2 源码已经就绪, 参见 这里
后续版本的发布时间,官方的时间安排参见 这里,摘抄如下:
Preliminary dates for the upcoming release:
Release: erts, emu,comp |Code stop |Documentation stop |Release Date17.0-rc2 2014-02-21 2014-02-21 2014-02-21 2014-02-26
17.0 2014-03-10 2014-03-17 2014-03-19 2014-03-26We will focus the time between 17.0-rc2 and 17.0 on bug fixes, improvements, and testing. Therefore you are most welcome to submit patches regarding such issues and we will try our best to include them before 17.0 is released.
Especially bugs introduced in 17.0-rcX.
R17 release note在 这里,闪亮点摘抄如下:
Maps, a new dictionary data type (experimental) 支持map数据结构,这是语言层面很大的变化,除了虚拟机和编译器的支持外,外围工具如debugger,profiler, ei, dialyzer等整个体系都需要大幅改变支持。
The {active, N} socket option for TCP, UDP, and SCTP 参看这篇:inet驱动新增加{active,N} socket选项
A new (optional) scheduler utilization balancing mechanism 这个特性改变了原来调度器full or not(在调度器用满之前,不会再用新的调度器)的特点, 添加了一种调度器之间利用率尽量平衡的调度算法。参见这篇:R17新的调度策略+sub
Migration of memory carriers has been enabled by default on all ERTS internal memory allocators 内存carriers在不同的调度器之间会互相迁移,提高内存的利用率。
Increased garbage collection tenure rate 垃圾回收更友好,同时异步化
Experimental “dirty schedulers” functionality 参见
Erlang/OTP 17.0-rc1 新引入的”脏调度器”浅析 引入的原因 例证NIF使用的误区
Funs can now be given names 参考:Erlang R16B03发布,R17已发力
Miscellaneous unicode support enhancements 全线支持unicode
A new, semantic version scheme for OTP and its applications 版本号管理更细致。
总体来看,VM的变化更多向着异步化和高性能(内存使用效率、CPU调度效率)的方向快速前进,系统也越来越强健, 一年一个大版本也很快。
祝玩得开心。
Post Footer automatically generated by wp-posturl plugin for wordpress.
erlang虚拟机内部文档
January 16th, 2014
1 comment
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: erlang虚拟机内部文档
erlang的运行期系统其实是个非常强悍的服务器,除了完善的分布式方面的实现,还有极高的性能。这些性能是通过压榨CPU、内存、锁获取到的,一句话概括,这些高性能实现是个宝藏。
但是一般的用户没有好的指导是很难挖到宝的,原因是这些高性能的获取和软硬件的体系紧密相关,以及erlang以消息为导向的哲学下的平衡,本身就超越了一般用户的使用场景。
幸运的是erlang开发团队认识到这个问题,开始为我们描述运行期内部的工作原理,相关的文档见这里
容我稍微摘抄下:
Carrier Migration
The ERTS memory allocators manage memory blocks in two types of raw memory chunks. We call these chunks of raw memory carriers. Singleblock carriers which only contain one large block, and multiblock carriers which contain multiple blocks. A carrier is typically created using mmap() on unix systems. However, how a carrier is created is of minor importance. An allocator instance typically manages a mixture of single- and multiblock carriers.
Post Footer automatically generated by wp-posturl plugin for wordpress.
Recent Comments