R16B port并行机制详解
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: R16B port并行机制详解
R16B发布的时候,其中一个很大的亮点就是R16B port并行机制, 摘抄官方的release note如下:
— Latency of signals sent from processes to ports — Signals
from processes to ports where previously always delivered
immediately. This kept latency for such communication to a
minimum, but it could cause lock contention which was very
expensive for the system as a whole. In order to keep this
latency low also in the future, most signals from processes
to ports are by default still delivered immediately as long
as no conflicts occur. Such conflicts include not being able
to acquire the port lock, but also include other conflicts.
When a conflict occur, the signal will be scheduled for
delivery at a later time. A scheduled signal delivery may
cause a higher latency for this specific communication, but
improves the overall performance of the system since it
reduce lock contention between schedulers. The default
behavior of only scheduling delivery of these signals on
conflict can be changed by passing the +spp command line flag
to erl(1). The behavior can also be changed on port basis
using the parallelism option of the open_port/2 BIF.
而且Jeff Martin同学也在qcon上发表了一篇文章特地提到这个事情,英文版见这里,中文版见这里
那么到底什么是R16B port并行机制呢?简单的说就是erl的这个选项:
+spp Bool
Set default scheduler hint for port parallelism. If set to true, the VM will schedule port tasks when it by this can improve the parallelism in the system. If set to false, the VM will try to perform port tasks immediately and by this improve latency at the expense of parallelism. If this flag has not been passed, the default scheduler hint for port parallelism is currently false. The default used can be inspected in runtime by calling erlang:system_info(port_parallelism). The default can be overriden on port creation by passing the parallelism option to open_port/2
作用呢?我们知道每个port都会有个锁来保证送给port的消息的先来后到,当有多个进程给port发送消息的话,必然要排队等前面的消息处理完毕。这是比较正常的行为。但是Erlang设计的哲学就是消息和异步通信,进程好好的时间浪费在排队上面总是不太爽。所以就搞了个port并行机制. 当进程发现需要排队的时候,他就把消息扔给port调度器,他自己就该干啥干啥去了,反正消息是异步的,他相信port调度器会把消息投递到。port调度器拿到用户委托的消息后,择机调度请求port去完成具体的任务。
类比下现实生活的例子。 比如说我去邮局寄快递,比如顺风快递,我寄了后,他会给我一个邮单号码,时候顺风会通知我邮包的情况,当然我也可以用这个邮单号码主动去查询状态。我到邮局一看,顺风快递的柜台只有一个工作人员在忙,而且寄东西人的队伍比较排很长了,这时候我有二个选择: 1. 在队伍的后面排队。 2. 我请求邮局的工作人员(比如保安)(当然可以给点小费)把我的邮包先收下,在寄东西人少的时候帮我寄下,而我就可以走了。 虽然我多花钱了,但是我花在上面的时间少了,这个小费可以挣的回来的。
port并行机制也是类似的原理。启用这个机制有二种方法:
1. 全局的。erl +spp Bool
2. per port的。open_port(PortName, PortSettings)的时候打开{parallelism, true}选项。
但是任何事情都有二面性。打开这个选项后需要注意什么呢?
我们还是拿前面的寄快递的例子来看,如果每个人都象我这样的都把邮包委托给保安去寄的话,那人多的话会有什么情况呢?保安那边有成堆的邮件,他领导一看,肯定要生气了,所以保安肯定会限制邮包数目。超过了,他就不接了。所以这就是调度器的水位线。而且顺风快递工作人员也有水位线,不如全杭州的人都来寄邮件他受的了?
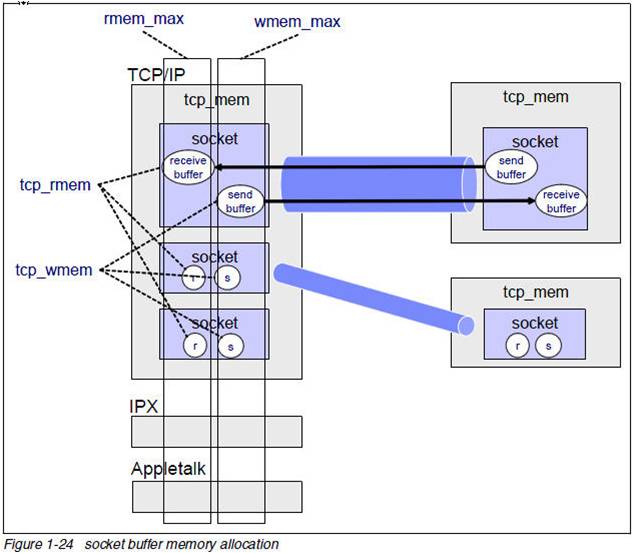
那这二个水位线分别是多少呢? 我之前写的这篇文章 gen_tcp发送缓冲区以及水位线问题分析 解释的很清楚,我简单的复述下:
1. port自己的水位线,比如说inet_tcp是:
#define INET_HIGH_WATERMARK (1024*8) /* 8k pending high => busy */
#define INET_LOW_WATERMARK (1024*4) /* 4k pending => allow more */
这个水位线可以透过inet:setopts选项来设置:
{low_watermark, Size}
{high_watermark, Size} (TCP/IP sockets)
2. MSGQ高低水位线也是8/4K,最小值是1, 高不封顶。当然也有选项可以设置。
{high_msgq_watermark, Size}
{low_msgq_watermark, Size}
这篇文章还解释了“A signal delivery”这个动作。每个port都要把消息发送出去处理了才有意义,那么这个发送动作其实就是call_driver_outputv, 调用port特有的driver_outputv回调函数去做实际的事情。说白了port并行机制就是控制什么时候调用call_driver_outputv, 从原来的直接调,改成如果条件不合适,就让port调度器线程择机来调用。
小结:通过port并行机制可以大大提高整个VM中大量port的吞吐量,对于port或者网络密集型(gen_tcp就是个port)的应用会有很大的帮助。
祝玩得开心!
Post Footer automatically generated by wp-posturl plugin for wordpress.

Recent Comments