量化Erlang进程调度的代价
原创文章,转载请注明: 转载自系统技术非业余研究
本文链接地址: 量化Erlang进程调度的代价
我们都知道erlang的基本哲学之一就是“小消息大计算”,简单的说就是尽可能的在消息里面携带完整的计算需要的信息,然后计算要尽可能的多,最好远超过消息传递的代价。但是为什么要这样呢?erlang消息发送的效率是很高的, 参见这篇文章
Roughly speaking, I’m seeing 3.4 million deliveries per second one-way, and 1.4 million roundtrips per second (2.8 million deliveries per second) in a ping-pong setup in the same environment as previously – a 2.8GHz Pentium 4 with 1MB cache.
在我的机器上的演示下看看具体的数字:
$ erl Erlang R15B03 (erts-5.9.3.1) [source] [64-bit] [smp:16:16] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.9.3.1 (abort with ^G) 1> ipctest:pingpong(). 832296.5692402497 2>
大概83万每秒个消息pingpong,测试程序涉及到二个Erlang进程ping和pong.
一个完整的流程涉及到 1. ping进程运行 2. ping进程等pong消息被切出。 3. pong运行 4. pong等ping消息被切出。这个流程涉及到二次Erlang进程的调度。
这是一个典型的erlang使用的场景,我们现在的问题是到底一个erlang进程调度的开销是多少?
从erts的实现来看,erlang会调用schedule()函数来选择下一个要调度的进程,而真正swapin和swapout的代价并不高,那我们来统计下schedule的开销。
还是祭出我们伟大的stap,写段调查代码先:
$ cat sch.stp
global total, coll_sch, sch
global exclude_sys_schedule
probe process("beam.smp").function("schedule") {
sch[tid()] = gettimeofday_ns();
total++;
}
probe process("beam.smp").function("schedule").return {
tid = tid();
e = gettimeofday_ns() - sch[tid];
if (exclude_sys_schedule && e > 10 * 1000 * 1000 ) coll_sch <<< 0;
else coll_sch <<< e;
}
function print_colls () {
prt_line = 0;
if(@count(coll_sch) >0) {
printf("total %d, avg %d ns\n", total, @avg(coll_sch));
printf("===========erts schedule(ns)===========\n");
print(@hist_log(coll_sch));
prt_line = 1;
}
if(prt_line) printf("--------------------------------------------------------------\n");
delete coll_sch;
delete sch;
delete total;
}
probe timer.s(1) {
print_colls();
}
probe begin {
exclude_sys_schedule = $1
println("x:");
}
$ PATH=/usr/local/lib/erlang/erts-5.9.3.1/bin/:$PATH sudo stap sch.stp 1
x:
如果调度器在不忙或者调度足够多的进程后,需要收割epoll事件,也就是会调用sys_schedule,这个时间通常会是ms级别的,我们将之排除掉,避免对平均时间的很大干扰。
然后我们运行上面的测试程序,我们收集到数据先下图:
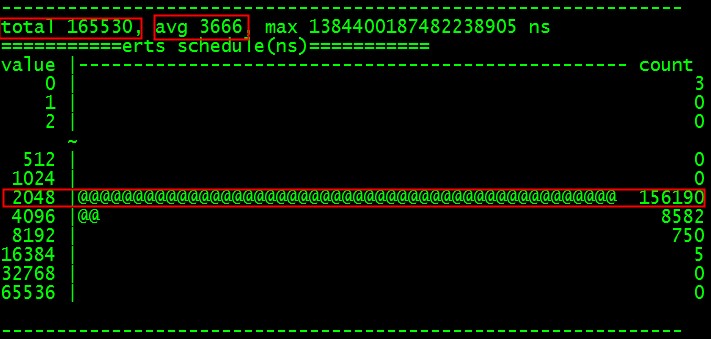
从图可以看出,我们的schedule每秒运行17万次左右,每次的代价大概是3个us左右。
我们再配合运行 erlang:statistics(context_switches)以及{_, Reds} = erlang:statistics(reductions) 就可以更准确的看出来上下文切换和运行的规约数字,见下图:
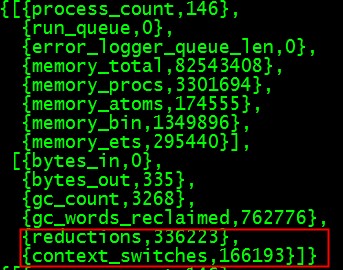
考虑到stap统计的时候需要用到锁,对目标程序的干扰还是很大的,我们来对比下有无干扰二种情况下的pingpong性能:
3> ipctest:pingpong().
100012.63959739232
4> ipctest:pingpong().
768416.6022861623
也就是说真实的类似pingpong调度开销大概是测试到的1/7, 大概是0.5us左右。可见小消息大计算是必要的。
小结: 量化数据是研究的基础, 这里抛砖引玉,希望引起大家的思考。
祝玩的开心!
Post Footer automatically generated by wp-posturl plugin for wordpress.
Recent Comments